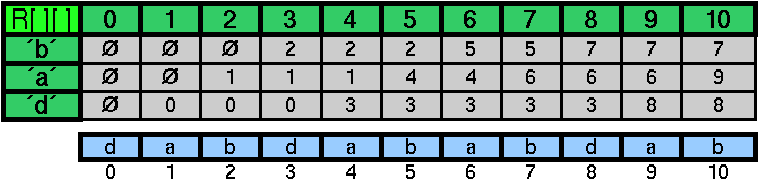
Bei der "Bad-Character-Rule" wird für das Suchmuster beim Preprocessing eine Liste erstellt, die für jedes Zeichen und jede Position im Suchmuster angibt, wann dieses Zeichen links von jener Position nochmal vorkommt. Dies ist streng genommen die "extended Bad-Character-Rule". Beim original Boyer-Moore Algorithmus wird nur das jeweils rechteste Vorkommen eines Zeichens im Suchmuster gespeichert.
Das Preprocessing kann auf verschiedene Arten implementiert werden, wobei immer zwischen benötigter Preprocessing-Zeit, der Größe des benötigten Arrays und der Zugriffszeit während der Suche abgewogen werden muß. Für das Preprocessing werden übrigens grundsätzlich keine N-Boxes benötigt.
Trifft man während des Vergleichens auf ein Mismatch, so schaut man in der Tabelle nach, an welcher Stelle das unpassende ("bad charakter") Zeichen links vom Mismatch im Suchmuster nochmal vorkommt und schiebt dann das Suchmuster soweit nach rechts, bis dieses Zeichen an der Stelle des Mismatch liegt. Kommt das Zeichen im Suchmuster gar nicht mehr vor, kann man das Suchmuster ganz am Mismatch vorbeischieben.
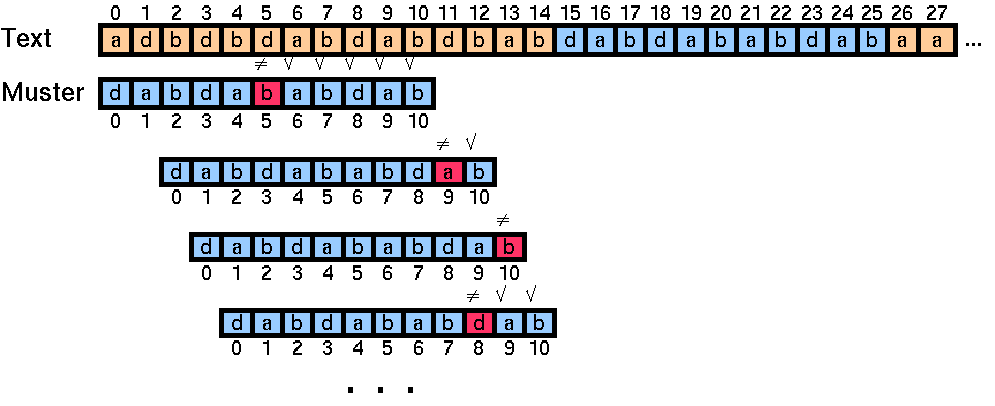
Im Beispiel sind die Sprungweiten immer recht klein. Das liegt daran, daß das Suchmuster nur aus einem sehr kleinen Alphabet (drei Zeichen) aufgebaut ist. Bestehen Text und Suchmuster nur aus ein und dem selben Zeichen ("worst case"), so führt die "Bad-Character-Rule" sogar zu einer quadratischen Laufzeit.
Trotzdem erweist sich diese Regel in der Praxis als recht effizient wenn ein großes Alphabet vorliegt, wie dies zum Beispiel bei der deutschen Sprache der Fall ist.
| Vorherige Folie | Zurück zum Index | Nächste Folie |